人工智能AI培训_机器学习之K近邻算法
1.k近邻简介k近邻法(k-nearest neighbor,k-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法。它的工作原理是:存在一个样本数据集合,也称作为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系。输入没有标签的新数据后,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
举个简单的例子,我们可以使用k-近邻算法分类一个电影是爱情片还是动作片。
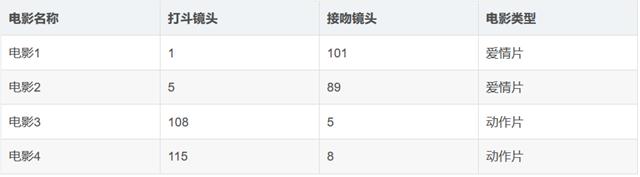
图1 上表每部电影的打斗镜头数、接吻镜头数以及电影类型
上表就是我们已有的数据集合,也就是训练样本集。这个数据集有两个特征,即打斗镜头数和接吻镜头数。除此之外,我们也知道每个电影的所属类型,即分类标签。用肉眼粗略地观察,接吻镜头多的,是爱情片。打斗镜头多的,是动作片。以我们多年的看片经验,这个分类还算合理。如果现在给我一部电影,你告诉我这个电影打斗镜头数和接吻镜头数。不告诉我这个电影类型,我可以根据你给我的信息进行判断,这个电影是属于爱情片还是动作片。而k-近邻算法也可以像我们人一样做到这一点,不同的地方在于,我们的经验更”牛逼”,而k-邻近算法是靠已有的数据。比如,你告诉我这个电影打斗镜头数为2,接吻镜头数为102,我的经验会告诉你这个是爱情片,k-近邻算法也会告诉你这个是爱情片。你又告诉我另一个电影打斗镜头数为49,接吻镜头数为51,我”邪恶”的经验可能会告诉你,这有可能是个”爱情动作片”,画面太美,我不敢想象。(如果说,你不知道”爱情动作片”是什么?请评论留言与我联系,我需要你这样像我一样纯洁的朋友。) 但是k-近邻算法不会告诉你这些,因为在它的眼里,电影类型只有爱情片和动作片,它会提取样本集中特征最相似数据(最邻近)的分类标签,得到的结果可能是爱情片,也可能是动作片,但绝不会是”爱情动作片”。当然,这些取决于数据集的大小以及最近邻的判断标准等因素。
2.距离度量
我们已经知道k-近邻算法根据特征比较,然后提取样本集中特征最相似数据(最邻近)的分类标签。那么,如何进行比较呢?比如,我们还是以表2为例,怎么判断红色圆点标记的电影所属的类别呢?如下图所示:
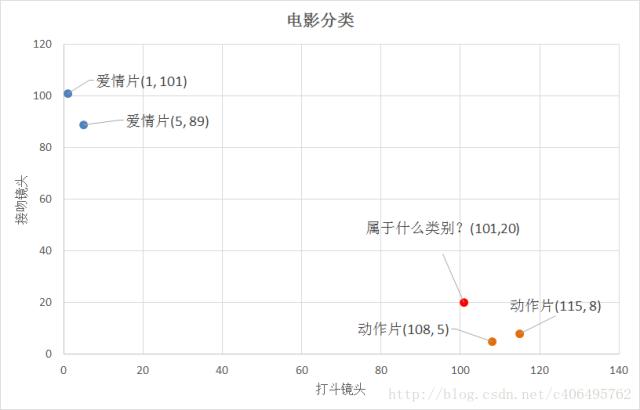
图2

通过计算可知,红色圆点标记的电影到动作片 (108,5)的距离最近,为16.55。如果算法直接根据这个结果,判断该红色圆点标记的电影为动作片,这个算法就是最近邻算法,而非k-近邻算法。那么k-邻近算法是什么呢?k-近邻算法步骤如下:
1.计算已知类别数据集中的点与当前点之间的距离;
2.按照距离递增次序排序;
3.选取与当前点距离最小的k个点;
4.确定前k个点所在类别的出现频率;
5.返回前k个点所出现频率最高的类别作为当前点的预测分类。
比如,现在我这个k值取3,那么在电影例子中,按距离依次排序的三个点分别是动作片(108,5)、动作片(115,8)、爱情片(5,89)。在这三个点中,动作片出现的频率为三分之二,爱情片出现的频率为三分之一,所以该红色圆点标记的电影为动作片。这个判别过程就是k-近邻算法。
3.k近邻算法实例-预测入住位置
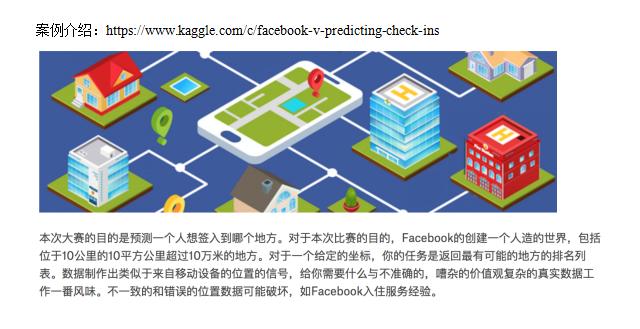
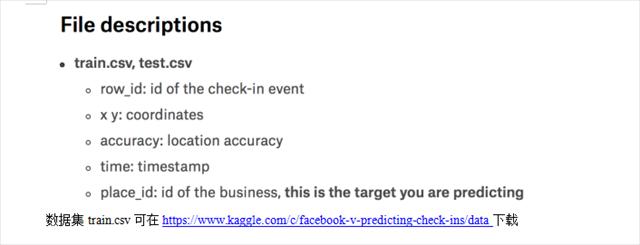
importpandasaspdfromsklearn.model_selectionimporttrain_test_split,GridSearchCVfromsklearn.neighborsimportKNeighborsClassifierfromsklearn.preprocessingimportStandardScaler
'''k近邻'''defknncl():#读取数据data = pd.read_csv("../data/train.csv")
#处理数据,选择一部分数据data = data.query("x>1.0 & x <1.25 & y>2.5 & y<2.75")#处理时间戳 2016-10-21 20:30:00time_value = pd.to_datetime(data["time"])#将时间转成日历的格式 {"day":...,"hour":...}time_value = pd.DatetimeIndex(time_value)
#增加日期、小时、星期等几个特征data["day"] = time_value.daydata["hour"] = time_value.hour data["weekday"] = time_value.weekday
# 把时间戳特征删除data = data.drop(["time"],axis=1)
# 按place_id分组,统计每个位置的入住次数place_count = data.groupby("place_id").count()# print(place_count)# reset_index()将place_id单独一列
tf = place_count[place_count.row_id > 3].reset_index()# 把签到数据少于n个目标位置删除data = data[data['place_id'].isin(tf.place_id)]
# 取出数据中的特征值的目标值y = data['place_id']x = data.drop(['place_id'],axis=1)
# 数据集分割,分成训练集和测试集x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.25)
# 特征工程,标准化处理std = StandardScaler()# 对测试集和训练集的特征值进行标准化x_train = std.fit_transform(x_train)x_test = std.transform(x_test)
print(data.head(10))# 进行算法流程 # 超参数knn = KNeighborsClassifier()knn.fit(x_train,y_train)
y_predict = knn.predict(x_test) print("预测的目标签到位置为:",y_predict)# 得出准确率print("预测的准确率:",knn.score(x_test,y_test))
#进行算法流程 # 超参数
#网络搜索# params = {"n_neighbors":[3,5,10]}# gc = GridSearchCV(knn,param_grid=params,cv=2)# gc.fit(x_train,y_train)## #预测数据# print("在测试集上准确率:",gc.score(x_test,y_test))# print("在交叉验证当中最好的结果:",gc.best_score_)# print("选择最好的模型是:",gc.best_estimator_)# print("每个超参数每次交叉验证的结果:",gc.cv_results_)return None
if__name__ =="__main__":knncl() |


