通俗来说,决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女孩的决策过程就是典型的分类树决策。相当于通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见。假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么这个可以用下图表示女孩的决策逻辑
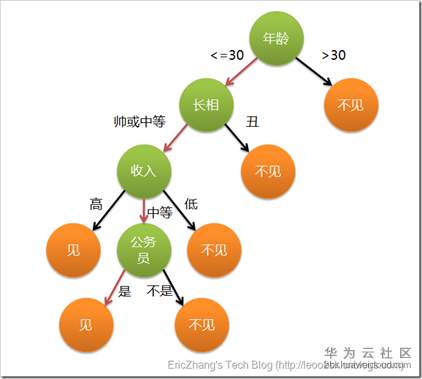
上图完整表达了这个女孩决定是否见一个约会对象的策略,其中绿色节点表示判断条件,橙色节点表示决策结果,箭头表示在一个判断条件在不同情况下的决策路径,图中红色箭头表示了上面例子中女孩的决策过程。
这幅图基本可以算是一颗决策树,说它“基本可以算”是因为图中的判定条件没有量化,如收入高中低等等,还不能算是严格意义上的决策树,如果将所有条件量化,则就变成真正的决策树了。
有了上面直观的认识,我们可以正式定义决策树了:
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
可以看到,决策树的决策过程非常直观,容易被人理解。目前决策树已经成功运用于医学、制造产业、天文学、分支生物学以及商业等诸多领域。
能消除不确定性的内容才能叫信息,而告诉你一个想都不用想的事实,那不叫信息。比如数据分析师的工作经常是要用数据中发现信息,有一天上班你告诉老大从数据中发现我们的用户性别有男有女。(这不废话吗?)这不叫信息,但是如果你告诉老大女性用户的登录频次、加购率,浏览商品数量远高于男性,且年龄段在25岁~30岁的女性用户消费金额最多,15-20岁最少,那么我相信你老大会眼前一亮的!!!
如何衡量信息量?1948年有一位科学家香农从引入热力学中的熵概念,得到了信息量的数据公式:
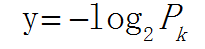
Pk代表信息发生的可能性,发生的可能性越大,概率越大,则信息越少,通常将这种可能性叫为不确定性,越有可能则越能确定则信息越少;比如中国与西班牙踢足球,中国获胜的信息量要远大于西班牙胜利(因为这可能性实在太低~~)
信息熵则是在信息的基础上,将有可能产生的信息定义为一个随机变量,那么变量的期望就是信息熵,比如上述例子中变量是赢家,有两个取值,中国或西班牙,两个都有自己的信息,再分别乘以概率再求和,就得到了这件事情的信息熵,公式如下:
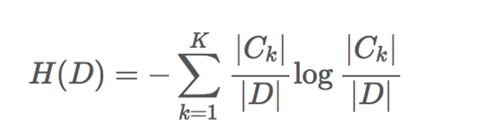
条件熵的计算:
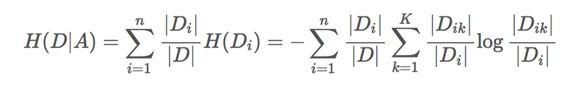
信息增益是决策树中ID3算法中用来进行特征选择的方法,就是用整体的信息熵减掉以按某一特征分裂后的条件熵,结果越大,说明这个特征越能消除不确定性,最极端的情况,按这个特征分裂后信息增益与信息熵一模一样,那说明这个特征就能获得唯一的结果了。
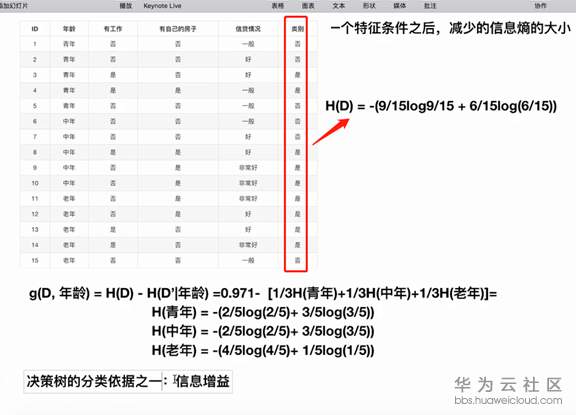
特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,即公式为:
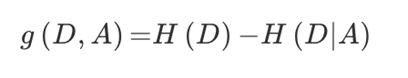
有以下数据,求出各个属性的信息增益:
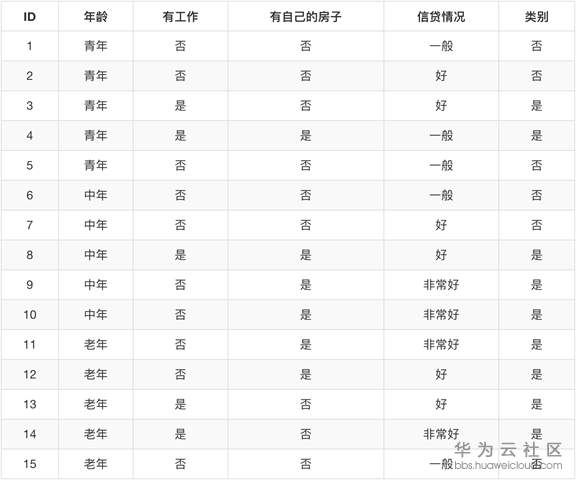
信息增益的计算

信息增益率是在信息增益的基础上,增加了一个关于选取的特征包含的类别的惩罚项,这主要是考虑到如果纯看信息增益,会导致包含类别越多的特征的信息增益越大,极端一点,有多少个样本,这个特征就有多少个类别,那么就会导致决策树非常浅。公式为:
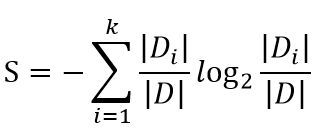
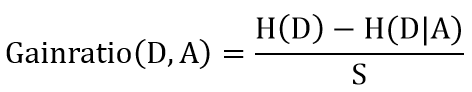
基尼系数也是一种衡量信息不确定性的方法,与信息熵计算出来的结果差距很小,基本可以忽略,但是基尼系数要计算快得多,因为没有对数,公式为:
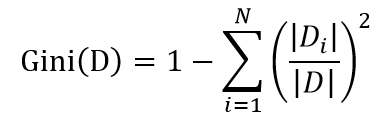
与信息熵一样,当类别概率趋于平均时,基尼系数越大
当按特征A分裂时,基尼系数的计算如下:
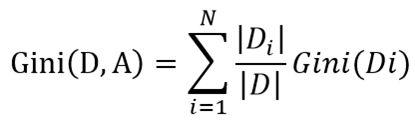
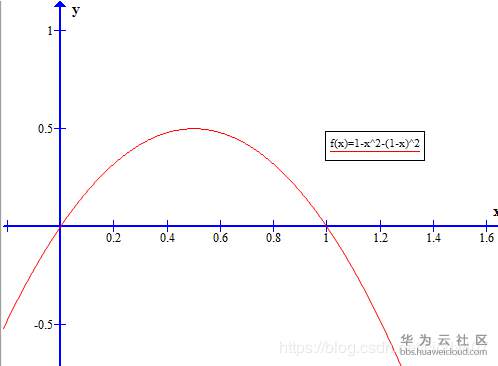
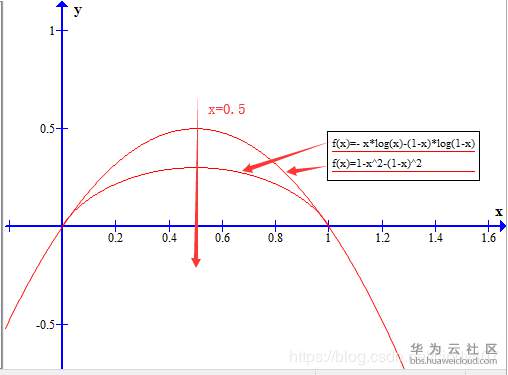
这是二分类时的基尼系数图像,与信息熵形状非常接近,从数据角度看,将信息熵在Pk=1处进行泰勒一阶展开,可以得到log2Pk≈1-Pk
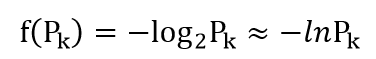
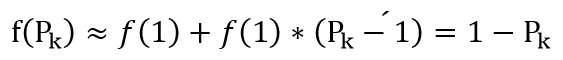
在泰坦尼克号和titanic2数据帧描述泰坦尼克号上的个别乘客的生存状态。在泰坦尼克号的数据帧不包含从剧组信息,但它确实包含了乘客的一半的实际年龄。关于泰坦尼克号旅客的数据的主要来源是百科全书Titanica。这里使用的数据集是由各种研究人员开始的。其中包括许多研究人员创建的旅客名单,由Michael A. Findlay编辑。
我们提取的数据集中的特征是票的类别,存活,乘坐班,年龄,登陆,home.dest,房间,票,船和性别。乘坐班是指乘客班(1,2,3),是社会经济阶层的代表。
其中age数据存在缺失。
根据以下数据来预测乘客生死

importpandasaspd if__name__ =="__main__": |
更多的技术内容,请访问学分高考公司网站www.togogo.net


微信扫码关注公众号
获取更多考试热门资料
